TOP 带着问题看源码
- LinkedList 采用的数据结构是什么
1. 继承和实现关系
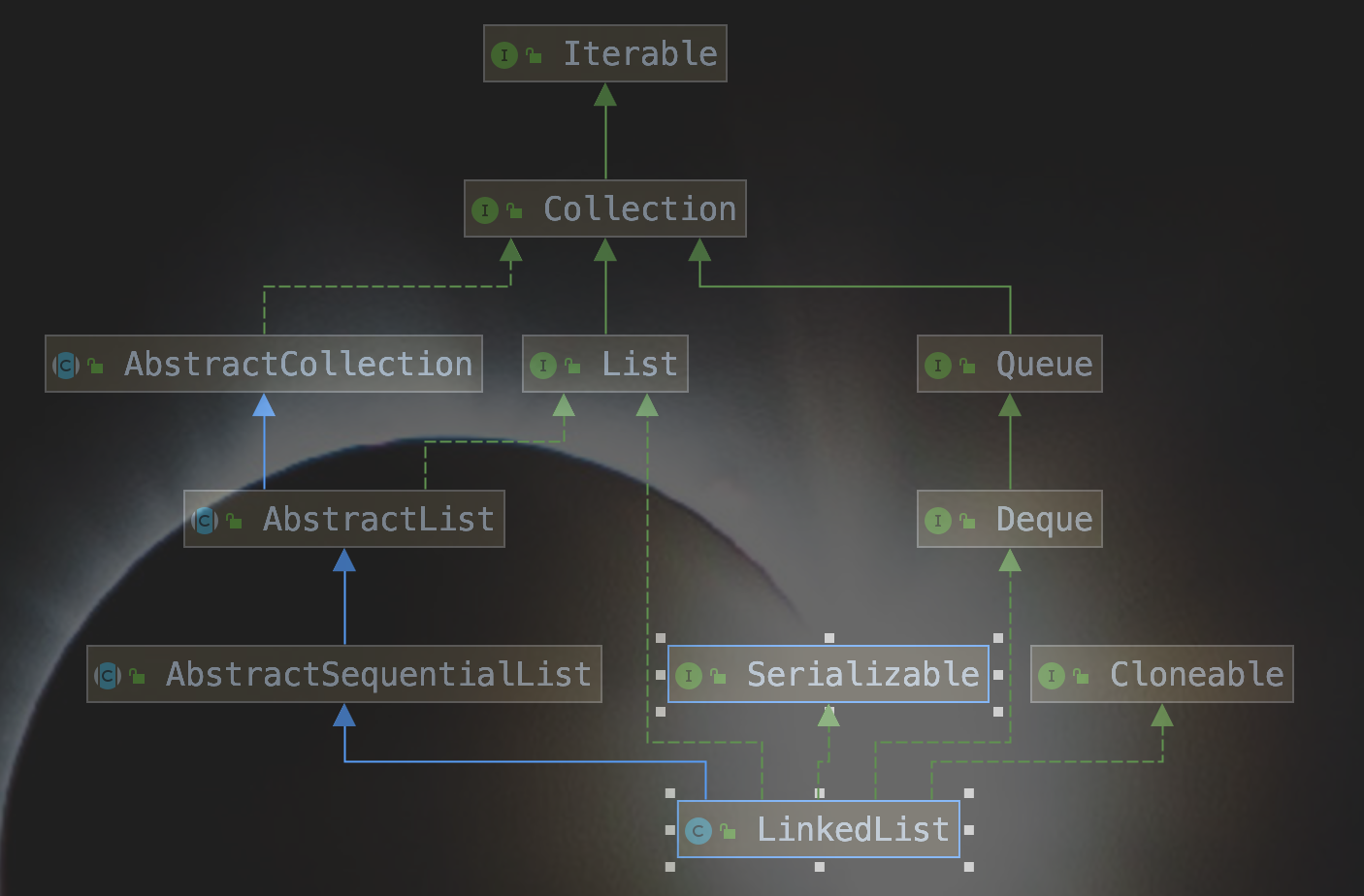
AbstractSequentialList 实现类
提供一些围绕着iterator的基础方法
List 接口
提供 list 功能
Deque 接口
提供双端操作功能,以此可以猜出 LinkedList 数据结构是一个双向链表
Cloneable 接口
标记该类对象能够被Object.clone()
Serializable 接口
标记该类是可序列化的
2. 成员变量分析
1 | // 容量 |
接下来看节点 Node的成员变量
1 | // 节点的值 |
回到 TOP 1 问题,根据实现可以明白其数据结构是一个双向链表
3. 构造方法分析
一个是默认无参,一个是带集合内容的。
把传来的集合新增入当前list
1 | public LinkedList(Collection<? extends E> c) { |
接下来看节点 Node的构造方法,根据入参默认维护两个指针。
1 | Node(Node<E> prev, E element, Node<E> next) { |
4. 核心方法分析
4.1 获取元素
先check,然后通过 node(index)方法取
1 | public E get(int index) { |
node 方法通过判断索引 index 的范围(若是大于一半集合容量,则从尾结点向前遍历,若小于则从头结点向后遍历)来尽量高效的取到对应的节点
4.2 新增元素
4.2.1 add(E e)
尾插
1 | public boolean add(E e) { |
构建一个next指针是null,prev指针是尾结点的新节点newNode,如果尾结点不为空则将尾结点的next结点指向newNode,否则将头结点指向newNode
1 | void linkLast(E e) { |
4.2.2 add(int index, E element)
先check,如果插入的还是尾部,则调用 linkLast 方法,否则先获取到索引 index 对应的节点然后调用 linkBefore 方法
1 | public void add(int index, E element) { |
构建一个 prev 指针是索引 index - 1 对应节点,next节点是索引 index 对应节点的新节点newNode **(图中绿色部分)**。然后把index节点的prev指向newNode (图中蓝色部分),如果要插入的是第一个位置,则把 first 指针指向newNode,否则维护剩余的指针关系(index - 1 节点的next指向newNode)(图中红色部分)

4.3 更新元素
根据下标位置获取节点,然后把节点的值进行覆盖
1 | public E set(int index, E element) { |
4.4 删除元素
4.4.1 remove(int index)
先check,然后先获取index对应节点最后调用unlink方法
1 | public E remove(int index) { |
同按照下标新增那块逻辑差不多,去除一个节点(prev next item置null),重新维护指针关系
1 | E unlink(Node<E> x) { |
4.4.2 remove(Object o)
遍历要找的元素的index,然后调用unlink方法
1 | public boolean remove(Object o) { |
4.4.3 clear()
遍历赋值null,size重置为0
